Context of Diacritics
| Category: | Projects |
| Published: | Aug 1 2013 |
| By: | Ondrej Jób |
Context of Diacritics is a research project and analysis of frequency and combinations of diacritical letters made to help type designers with refining the character sets of their fonts.
I love display typefaces. And I like when they’re packed with abundance of OpenType features, alternative glyphs and most of all — ligatures. Also, I come from a diacritics-intense environment, so when designing my fonts, I naturally want to equip all of the special glyphs with diacritics. But here comes the big question — how can one possibly know what diacritic variants exist for a given ligature?
I first ran into this problem when I was designing Klimax. The Plus style really asked for its ligatures, not only for aesthetic, but for functional reasons too. Among the blackness of the shapes, the irregularities of white spaces between some glyphs were seriously disrupting the ultrablack experience.
So I drew some 40 base ligatures and then I turned to Peter Biľak for help with their diacritical variants. He quickly sent me a list of glyphs, that needed to be added. His method was to include all possible diacritic combinations, but not combining diacritics from different languages. For example, for the hypothetical ru ligature, this method would correctly return řů as an existing combination in Czech and omit řü, because there’s no language using both ř and ü. However, the combination řú would also be returned as correct, since Czechs use both of the glyphs, but in reality, this combination does not exist in Czech nor any other language in the world. And here’s the problem — populating fonts with non-existent glyphs really isn’t the best practise, especially today, in the age of webfonts.
Earlier this year, I’ve begun with yet another display typeface with plenty of special letter combinations and all the diacritics conundrum started to bug me again. This time — being all on my own — I wanted to find the solution myself. After looking for an online resource for a couple of hours, I realized that there’s no database of diacritical combinations to be found anywhere on the internet. I was thinking — haven’t any type designer ever needed this before? How’s that possible?
So with my programming skills improving slowly but steadily, I decided to do the work and build the database myself for everyone to use. Before describing the process, I have to admit that I’m only a hobby-linguist and my coding and calculation techniques are far from perfect. However, I believe you will find the results of my effort correct and useful.
How it was made
I knew I could get the data I need only by analyzing a body of text. A text that is accessible and available in 26 languages I was planning to cover. First I thought that using the national corpuses is a good idea, but after looking into the Slovak one, which was overflowing with archaisms and bohemisms (words with Czech origin incorrectly used in Slovak) that are not used in real life anymore and would be returning inaccurate results, I didn’t want to risk to analyze text from corpuses for languages I don’t speak at all. Naturally, the next best destination for texts in multiple languages is Wikipedia.
So I wrote a little script, that would crawl the website and analyze texts from all of the 26 languages. As you probably know, the style of writing on Wikipedia can be slightly different from one topic to another. For my analysis, I decided to use articles about history, for more natural language and local names, and about natural sciences, for the special combinations that exist only in scientific terms (at least in Slovak language). The crawling and analysis was being performed until 2 million characters were analyzed from each language. For comparison, that’s like a book with more than 1000 pages.
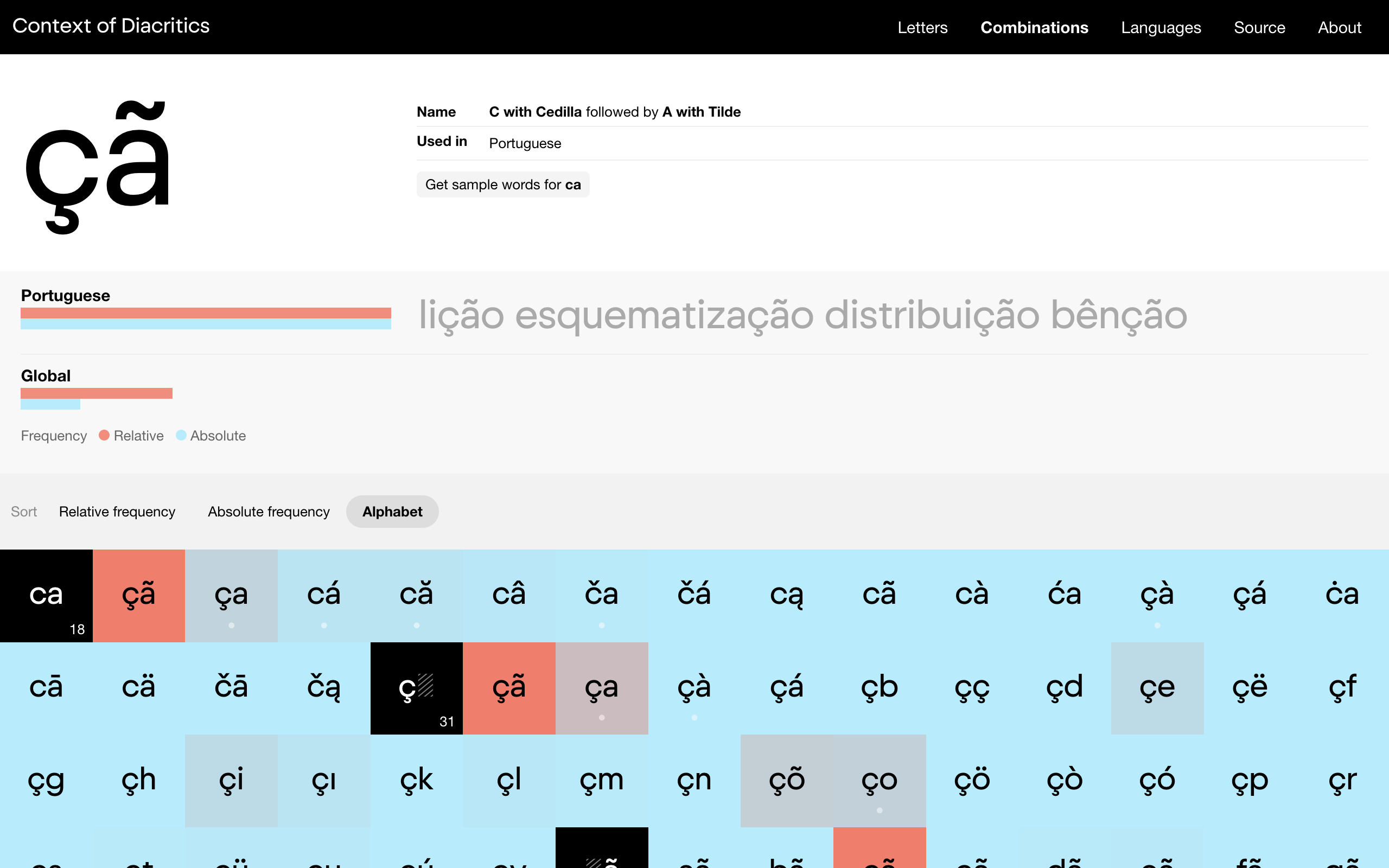
And what exactly was part of the analysis? First of all, the script recorded all contexts in which each letter with a diacritic mark can exist. This is the most important and probably most useful part of this project. But when doing all this crawling and analyzing, having to crunch through lots of text, why not collect some other data too? Well, frequency of every single diacritical letter and every possible diacritical combination was counted, position at the beginning or the end of words was noted, diacritical combinations that exist as stand-alone words were collected and a sample word for every single combination was recorded. However, because of the methods used, all this extra data is not and cannot be 100% accurate. You can read more about this in the project’s Disclaimer.
If you occasionally read Wikipedia (or love it as much as I do), you are well aware that grammar mistakes are quite common over there. This of course would affect the results and that’s why the data had to undergo another analysis — this time by real people, one native speaker for each analyzed language. Thanks to my studies in the Netherlands, I made a bunch of friends from all over the world, who covered most of the languages. For the few others, it was really no problem to find someone who knows someone. This world really is small. The “editors” went through the data, manually fixed errors and some of them even added what was missing. I can’t thank them enough for their fantastic help.
A quick HOW-TO
Let’s say you have the st ligature in your font and need to find out in what diacritical variations it exists in real life.
1. Go to Context of Diacritics
2. Click Combinations in the main menu on top of the page
3. In the grey Options bar, select View: Base Glyphs and Sort: Alphabet
4. Scroll down and click st
5. Voila!